# cs224n Lecture 8
부제 : Machine Learning이라는 새로운 task와 sequence-to-sequence 라는 새로운 architecture
# 개요
- Statistical Machine translation
- Word alignment
- Sequence-to-sequence model
, - Beam search decoding
- BLEU score
- bottleneck problem
- Attention
# Stochastic Machine translation
MT : translating a sentence from source language to the target language Machine Translation of the past.
Learn a probabilistic model from data
Want to find best English sentence
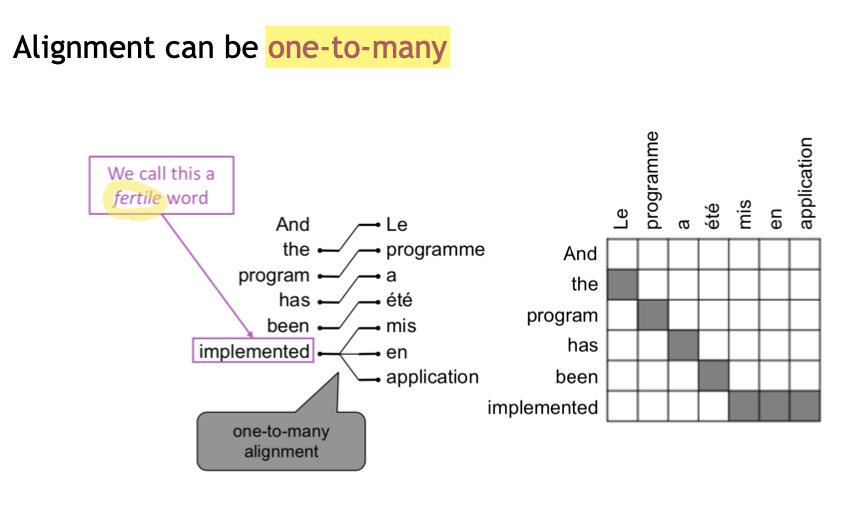
# Word alignment
How to learn translation model
TIP
Break it down furthur: Introduce latent
::: detail Latent Variables ???? :::
Alignment 까지 고려해서(
아무튼 SMT는 사람 손이 많이 가는 모델이었고 NN의 시대가 오면서 당연히 이를 이용한 MT 모델이 등장하게 되었다. seq2seq
# Sequence-to-squence model
하나의 NN을 이용한 Machine Translation으로 (2014년에 등장) 두 개의 RNN이 관련되어 있다. 쉽게 얘기해서 source sentence를 encoding하고 그 결과로 나온 hidden state을 가지고Decoder에 넣어서 target sentence를 생성하는 것이다.
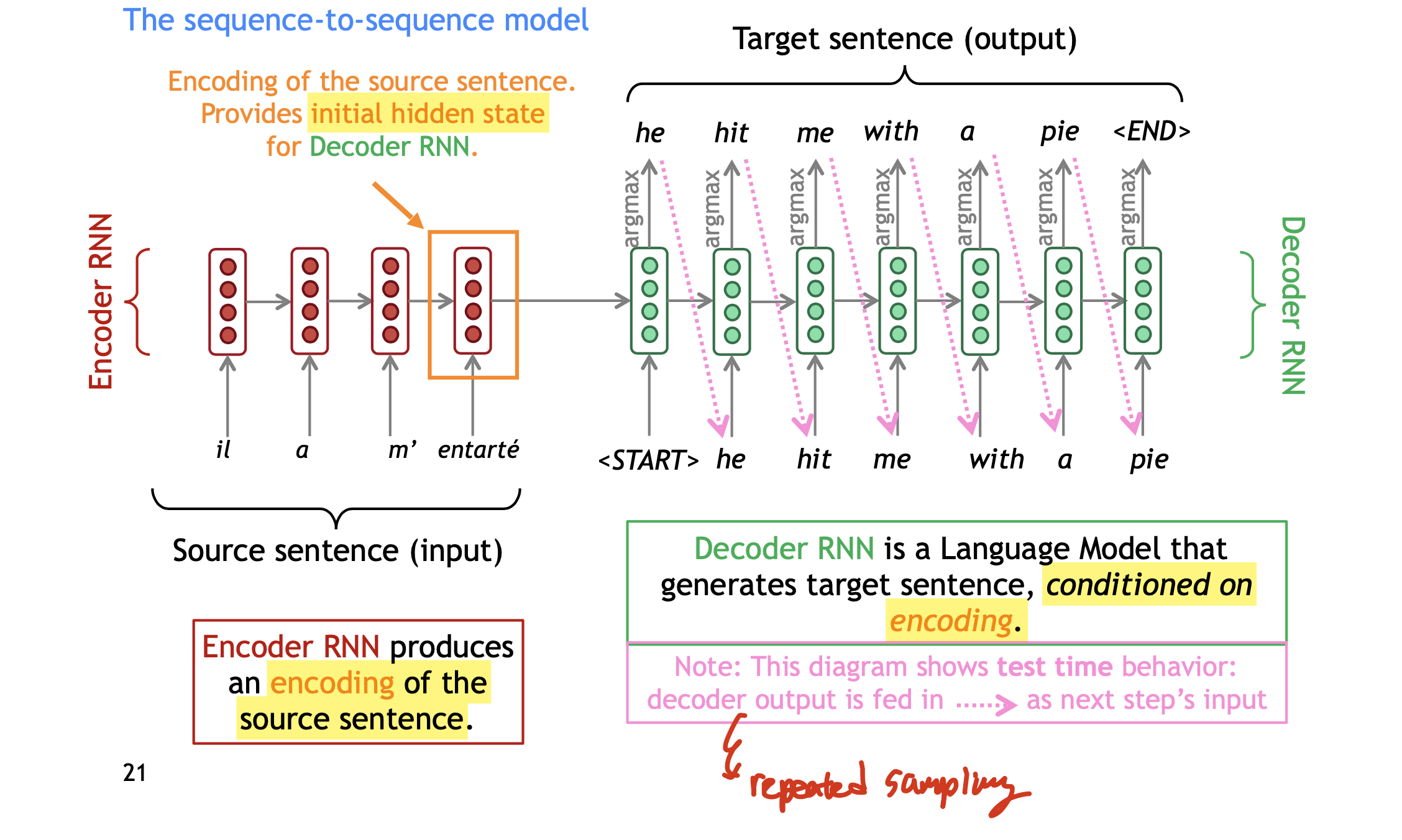
Seq2seq model은 Conditional Language model의 예시다. target sentence
NMT는
그래서 NMT를 어떻게 학습할 수 있는가? 매우 큰 Parallel corpus를 가지고 와랏.

::: detail Questions Is it necessary to do end-to-end training? -> separating training may result with problems in opimalization when they are put together. Optimalization of the seperate does not neccessarily suggest that they are optimal together. BUT unconditional 한 LM을 만들고 싶어 하는 경우에는 Decoder 만 따로 학습 시킬 수도 있겠다. ::: ::: detail Questions2 Should the length of the input sentences be fixed? -> No since the RNN-LM has pros in a way that they don't have any pre-defined window size. But in practice or implementation, Just because it is easier if you can assume the size of the length in each batch has same size you can use padding to enforce unary length to the sentences in a batch. And then make sure that you don't use any hidden state that came from the padding. :::
그리고 여기서 word vector는 다운로드 받을 수도 있고, 직접 학습시킬 수도 있다(6강에서 했던 얘기)
#
사실 Greedy Decoding이
아래에서 해야할 얘기를 여기서 좀 하면, beam search decoding을 하는데 있어서 k 개의 hypothesis 중에
WARNING
참고로 training data에 이런
# Beam search decoding
문제의식 : Greedy Decoding(단순히 각 hidden step 으로부터 argmax(softmax)를 하는 것은 문제가 있다. 왜냐하면 해당 step에서의 argmax가 전체 문장에서 argmax(
저장은 하는데 가장 probable 한 partial translations 를 k 만큼 저장하면서 따라가는 것이다(keep track of the k most probable partial translations) -> _hypothesis_라고 부른다. rmf그리고
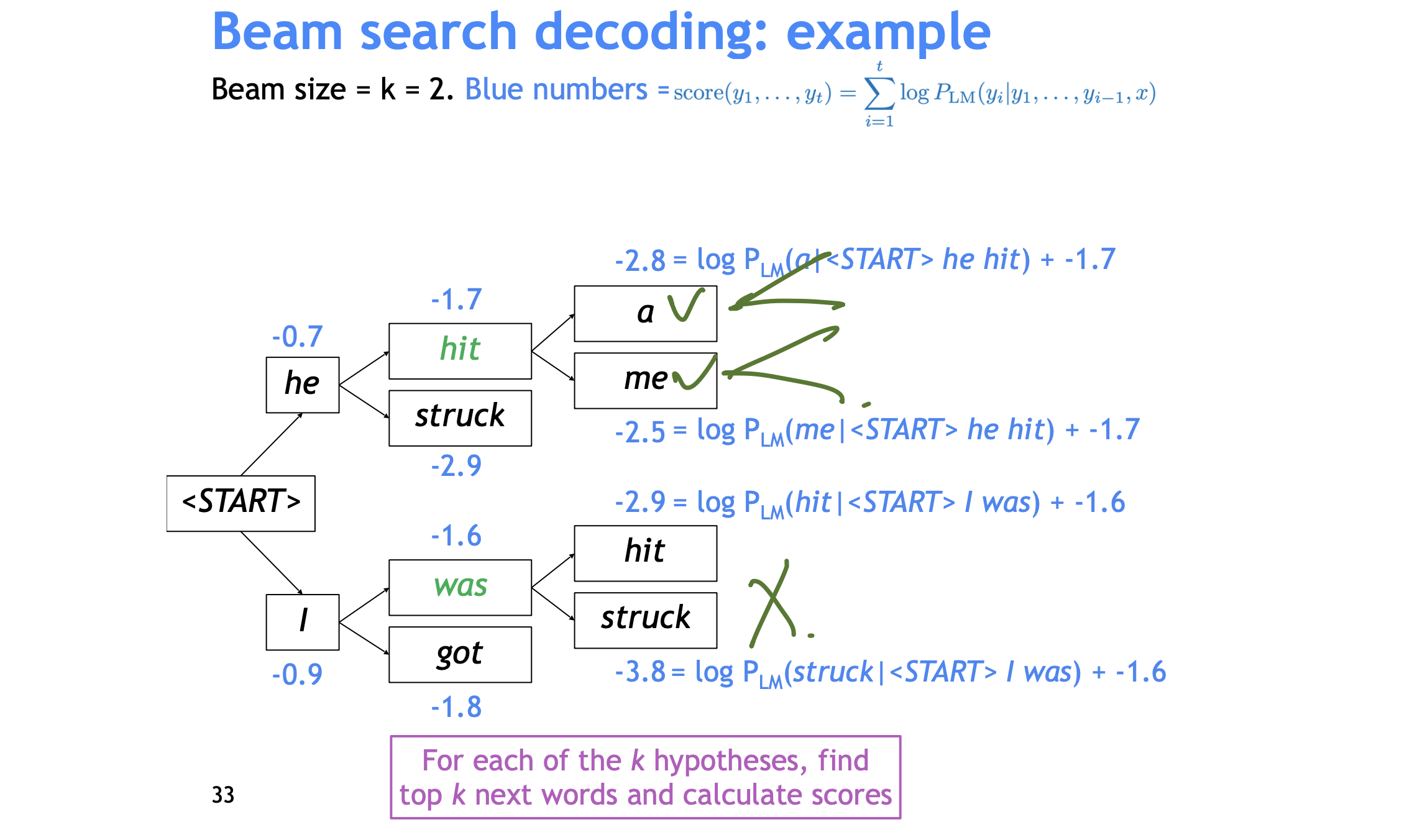
마지막으로 위의 식을 보면 길이가 짧은 hypothesis가 높은 확률을 가질 수 밖에 없는데 이를 해결하기 위해서
::: detail Smart Question Why not use normalized score during the beam search decoding? -> 사실 beam search를 하는 중에는 같은 길이의 hypothesis만 비교하는 것이기 때문에 굳이 costly한 나누기를 해줄 필요가 없다. :::
# Pros & Cons
일단 더 번역을 잘한다. 맥락을 더 잘 활용하고 비슷한 의미의 다른 문장들을 잘 활용한다(better use of phrase similarities). 한 개의 뉴럴넷을 end-to-end로 optimize하면 된다(뭐 굳더더기 subcomponents가 없다). 그래서 사람 손이 덜 간다. 그리고 언어페어 별로 범용으로 사용할 수 있는 모델이다(물론 학습은 각각 시켜야겠지만).
그런데 Less Interprate 하다(어떻게 돌아가는지를 모른다; NN 전반의 문제). 그리고 콘트롤하기 어렵다(어떤 규칙을 적용시키기 어렵다. 특정단어에 대한 규칙을 따로 적용하기가 어렵다). Safety 문제가 있다(욕을 못하게 할 수가 없다).
# BLEU score
Bilingual Evaluation Understudy. Computes Similarity score based on n-gram(기계가 번역한 결과를 n-gram으로 나타냈을 때 그 n-gram이 인간 번역에서도 나타나는지 확인하는 것) and penalty for too-short system ranslations(n-gram은 conservative한 문장에 대해서 점수를 다 줘버리기 때문이다. 잘못해석할까봐 짧고 추상적으로 번역하는 부분에 대한 penalty)
하지만 BLEU도 완벽하지 않은데, n-gram 하고 겹치지 않더라도 좋은 번역일 수 있기 때문이다. 그래도 이부분은 사람 번역이랑 비교를 하는 것이니 믿고 맡겨도 되지 않을까??
참고로 BLEU는 precision을 구한다.
하지만 아직 NMT에도 부족한 점이 많다.
Out-of-vocabulary words -> subword modeling(character based modle)
Domain mismatch between train and test data
Maintaining context over longer text -> 강의에서는 한문장만 번역하는 걸 보여줬지만, 도큐먼트 단위로 번역하려면 expensive 해진다.
Low-resource Language pairs over all common sense 기계에 적용하는건 여전히 어렵다. NMT picks up biases in training data -> 젠더가 없는 입력 데이터를 젠더가 있는 문장으로 출력하는 경우(train data에 더 많이 등장하는 젠더가 등장한다). 입력 데이터가 noise에 불과한 경우에는 오토파일럿으로 영어 decoder를 사용하는 것으로 알려져 있다. You neve know it would happen untill they happen.
# Bottleneck problem
RNN에 한 개 종류의 vector에 계속 정보를 주입하기 때문에 기본적으로 bottleneck probelm이 발생한다.
encoder가 너무 많이 돌면(인풋 문장, 도튜먼트가 너무 길면) 끝에 가서는 첫 단어에 대한 정보가 hidden state 안에서 거의 사라져버렸을 가능성이 있다.
# Attention
bottle neck problem을 해결하고자 나온 새로운 vanilla seq2seq NMT system : Attention
Main Idea
On each step of the decoder, use direct connection to the encoder to focus on a particular part of the source sequence.
- decoder hidden layer를 가지고 encoder hidden state 과 dot product를 수행해 총 N개(input length) 만큼의 attention score를 구한다.
- 이 attention score에 softmax를 적용해 Attention distribution을 구한다.
- Attention distribution을 이용해 encoder hidden state의 weighted sum을 구한다. 이것이 Attention output
- Attention output 을 decoder hidden state과 concatenate 해서 사용한다(이를 이용해

이를 통해 vanishing gradient problem 를 해결할 수도 있고, NN가 어디에 집중하고 있는지를 알아낼 수도 있어 NMT가 interpretable 하지 못하다는 문제를 극복할 수 있었다.
# Variant of attention
attention score(scalar 값들)를 구하는데 있어서 variants가 세가지 정도 존재한다. Basic dot-product attention, Multiplicative attention, Additive attention