# cs224n 10강 정리
# 개요
- Machine Comprehension
- Extrative QA
- SQUAD 1.0 vs SQUAD 2.0
- F1 score
- Stanford attentive Reader, BiDAF, FusionNet
# Machine Comprehension
Information retrieval 관련 되는 도큐먼트들을 찾아서 보여주는 방법으로는 한계가 있다. 그래서 Reading Comprehension 방법을 추가해서 해결한다. 이 방법은 최초의 NLP에서 시도했던 problem 중 하나다(1977, Lynette Hirschman 1999)
Burges (2013)가 Machin Comprehension이 사실 머신러닝의 주요한 문제임을 지적하면서 그 개념을 제시했다.
Definition
A machine comrehends a passage of text if, for any question regarding that text that can be answered correctly by a majority of native speakers, that mahcnie can provide a stirng which those speakers would agree both answers that question, and does not contain information irrelevatn to that question.
# Extrative QA
Often referred to as reading comprehension. Its data is formed from triple. 즉 질문이 있으면 주어진 도큐먼트로부터 정답을 추출하여 답을 출력하는 task를 의미하고 아래의 SQUAD가 이러한 task에 적합한 데이터를 모아두고 있다. No yes or no questions, just questions that could be anwsered in subsequent string or span.
# SQUAD
3 사람이 답한 바를 정답으로 한다.
참고로 BERT(ensemble) from Google AI Language가가장 정답률이 높다.
SQUAD version 2.0 는 1.0에는 모든 정답이 paragraph에 있다는 단점이 있었다. 그래서 2.0에는 No answer가 정답인 데이터가 들어갔다.
오답을 통해서 시스템이 어떻게 돌아가는 지를 확인할 수도 있다. 1234 정답 확인
그런데 이런 방식(paragraph를 보고 그에 기반한 질문이 작성되었다는 점)은 사실 task를 unnaturaly easy 하게 만든다. NLI 같은 정보를 사용하지 않는 데이터셋이다(he, it, she)
# F1 score
Precision =
F1 is more reliable and taken as primary than Exact Match.
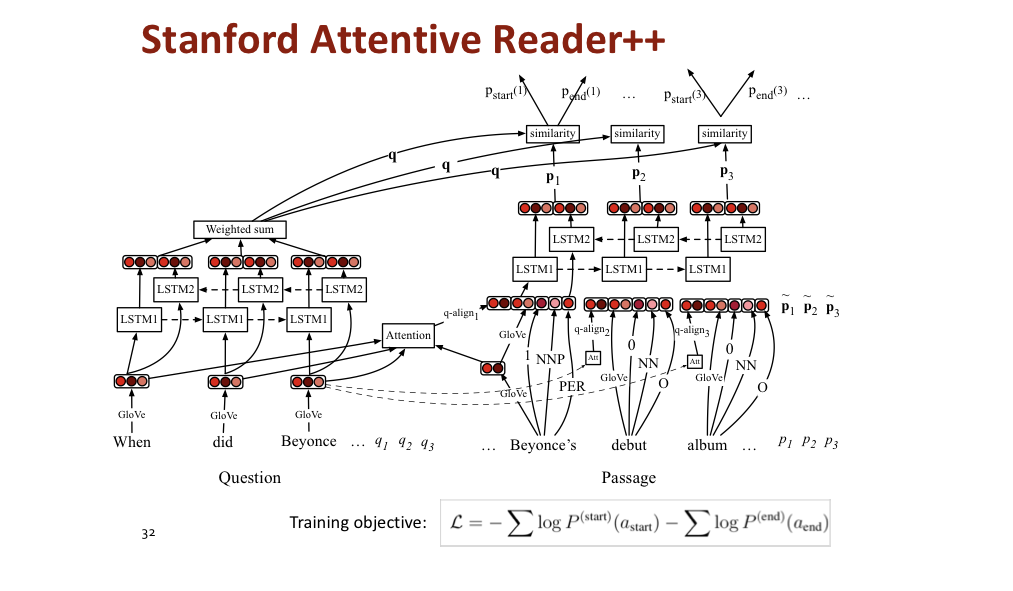
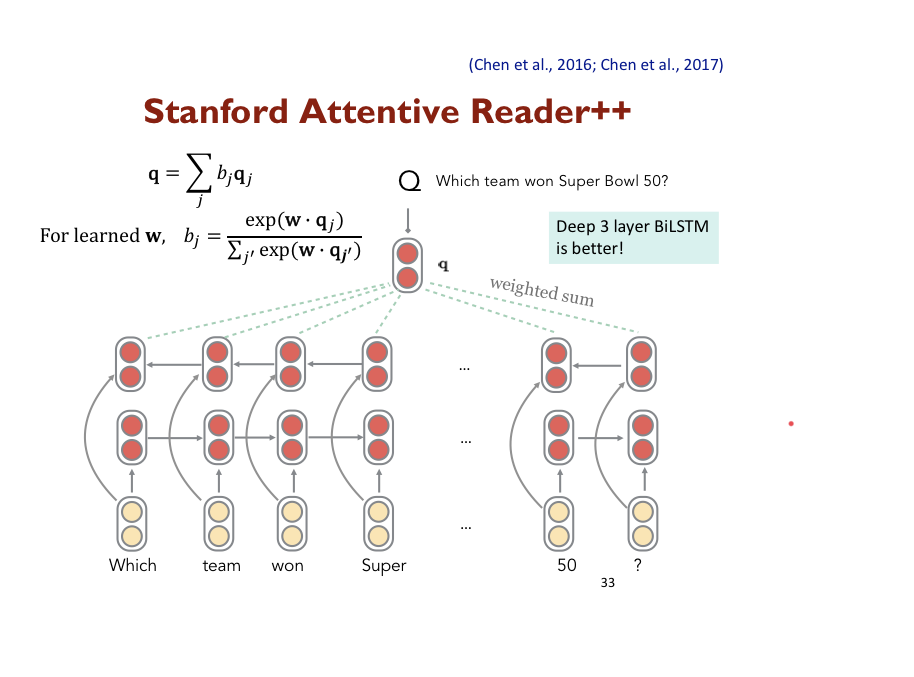
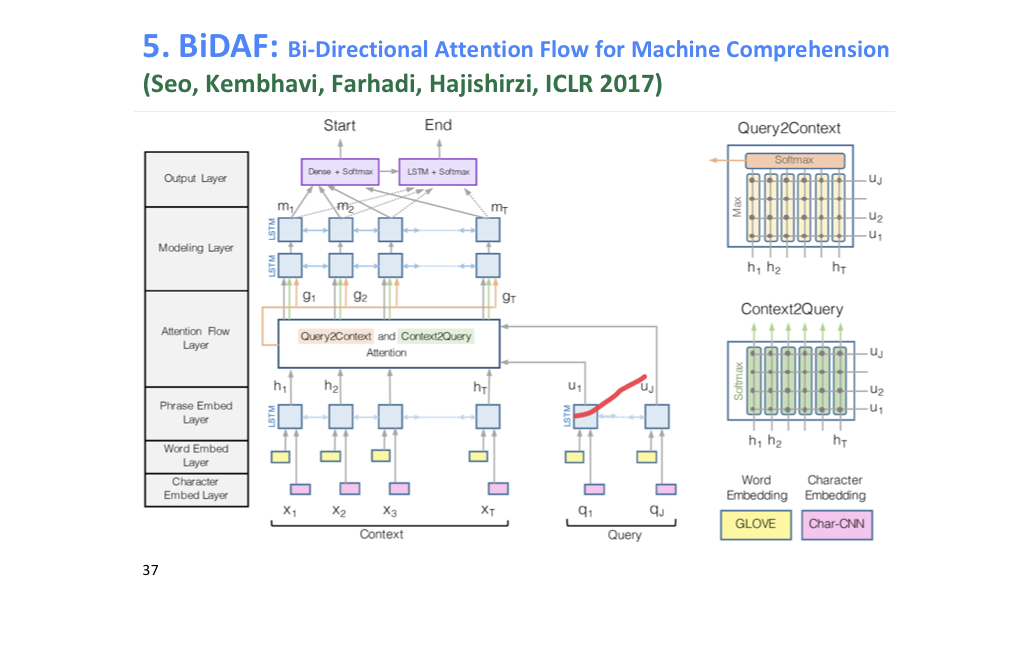
# Stanford attentive Reader, BiDAF, FusionNet
상대적으로 간단한 예시를 보여준다.