# CS224n 6강
# 개요
- Language modeling
- N-gram, sparsity problem
- Generating text with fixed window
- RNN
- Back propgation through time
- Generating text with RNN
- Perplexity
# Language Modeling
Definition
Langauge Modeling is the task of predicting "ANSWER".
ANSWER
what word comes next.
보다 정확히는 sequence of words 가 주어졌을 때, 다음 단어의 probability distribution 을 계산하는 것
또는 어떤 텍스트에 확률을 지정하는 시스템(A system that assigns probablity to a piece of text)으로 볼 수도 있다.
핸드폰에서 자동단어 완성해주는 것도 LM의 일종이다.
# N-gram, sparsity problem
그래서 이런 LM을 학습하기 위해서는 어떻게 해야하는가?
Quote
How to learn a Language Model?
Deep Learning의 시대가 오기 전에는 n-gram LM 을사용하였다. (자세한 사항은 슬라이드 참고)
n-gram 에서는 우선, markov assumption(어떤 단어는 그 앞의 n-1개의 단어에만 의존한다
하지만 sparcity, storage problem 이 있다. Sparcity problem 이란 분자가 0이 되는 경우, 즉 token 이 training 데이터에서 드러나지 않는 경우가 많아 발생한다. 충분히 생성가능한 문장임에도 확률이 낮다는 이유로 절대 나타나지 않을 수 있다는 말이다. 이를 해결하기 위해 작은 델타 값을 더해주기도 하고, 만약 분모가 0이라면 window size를 줄여서 분모가 0 보다 커지도록 한다.
LM은 문장을 생성하는데 사용되기도 하는데, n-gram으로는 굉장히 grammatical 한 문장을 생성할 수 있지만 이는 매우 incoherent 하다는 것을 확인할 수 있다.
Today the price of gold per ton, while production of shoe lasts and shoe insdustry, the bank intervened just after it considered rejected an imf demand to rebuild ...
# Generating Texts with Fixed Window
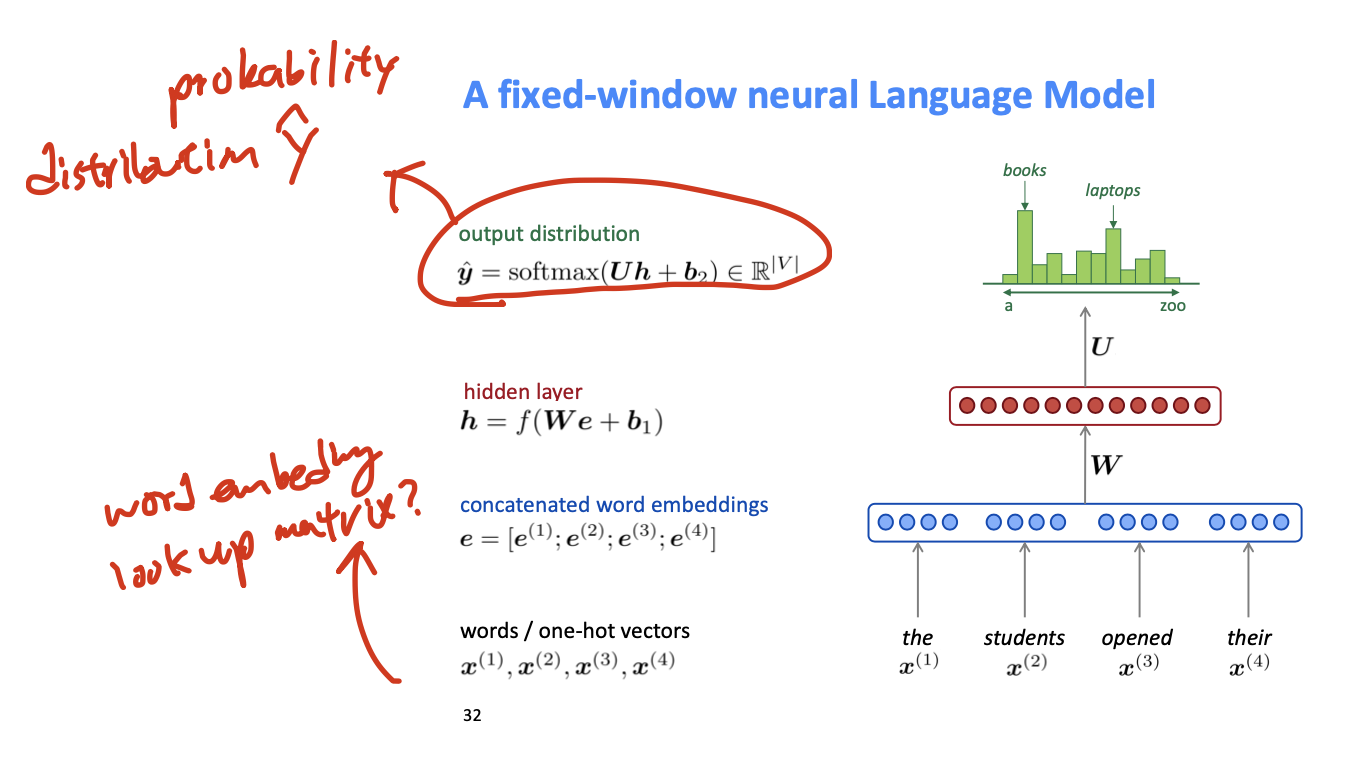 No sparsity problem, Don't need to store all observed n-grams 라는 문제가 있다.
No sparsity problem, Don't need to store all observed n-grams 라는 문제가 있다.
단점: Fixed window is too small; Enlarging window enlarges W; window can never be large enough; W 의 각각의 벡터가 서로 연관되지 못한다(there should be lot of commonalities in how you process the incoming word embeddings).; -> 일단 기본적으로 window의 크기에 제한을 받는다는 문제가 있다.
# RNN
window의 크기에 제한 받지 않는 모델, sequence의 길이가 얼마나 길든 문제가 되지 않는다.
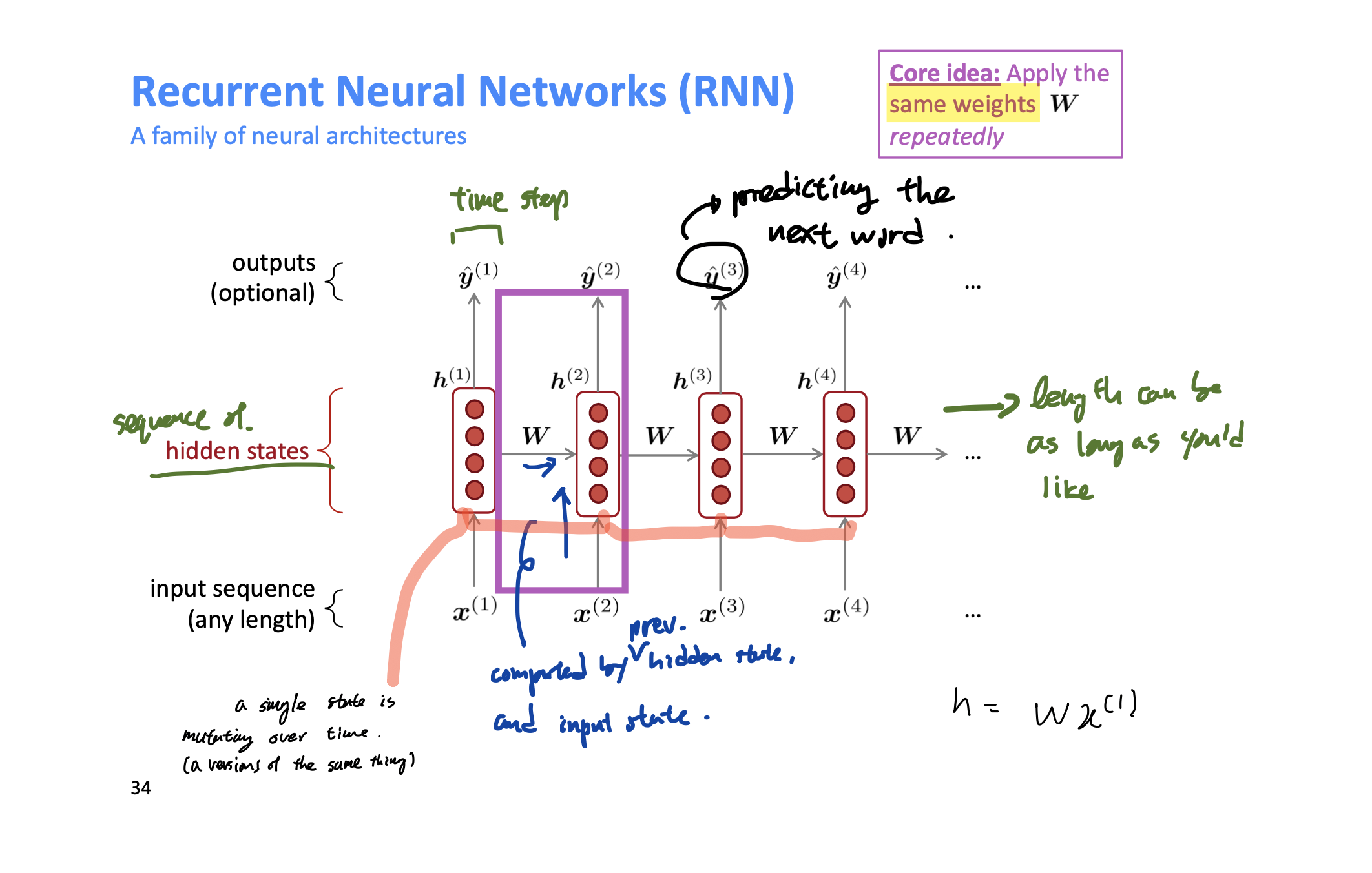
장점: step t 에서의 연산은 여러 스텝 이전의 정보를 사용할 수 있다(in theory; 앞의 예시에서 proctor가 중요한 정보를 담고 있다는 점을 반영할 수 있다는 얘기); W의 크기가 일정하다(2개의 W가 있긴하지만); 동일한 W가 각각의 input에 동일하게 적용되기 때문에 (W 의 각각의 벡터가 서로 연관되지 못하는) window base 모델에서의 단점을 극복할 수 있다. 따라서 한 input에 대해서 잘 효과적인 학습이 되면 그 이점을 모든 input에 대해 누릴 수 있다는 장점이 있다;
단점: 연산이 느리다; 실전에서는 여러 스텝 이전의 정보에 접근이 어렵다;
::: Danger
Why is the same transfromation (W_h, W_e) applied each time? While a sequence of words could always appear in Different contexts?
와씨 개좋은 질문이다
"You are learning a general function, not just with one word in blank. A general function of how you should deal with a word given the word so far. In other word RNN is a method to learn a general representation of language and context so far.
And the hidden states are vector of lenghts almost 500 or more. So their capacities are big enough to hold a lot of informations about different things in their different postions." ~~ 스탠 학생들 똑똑하다~~
:::
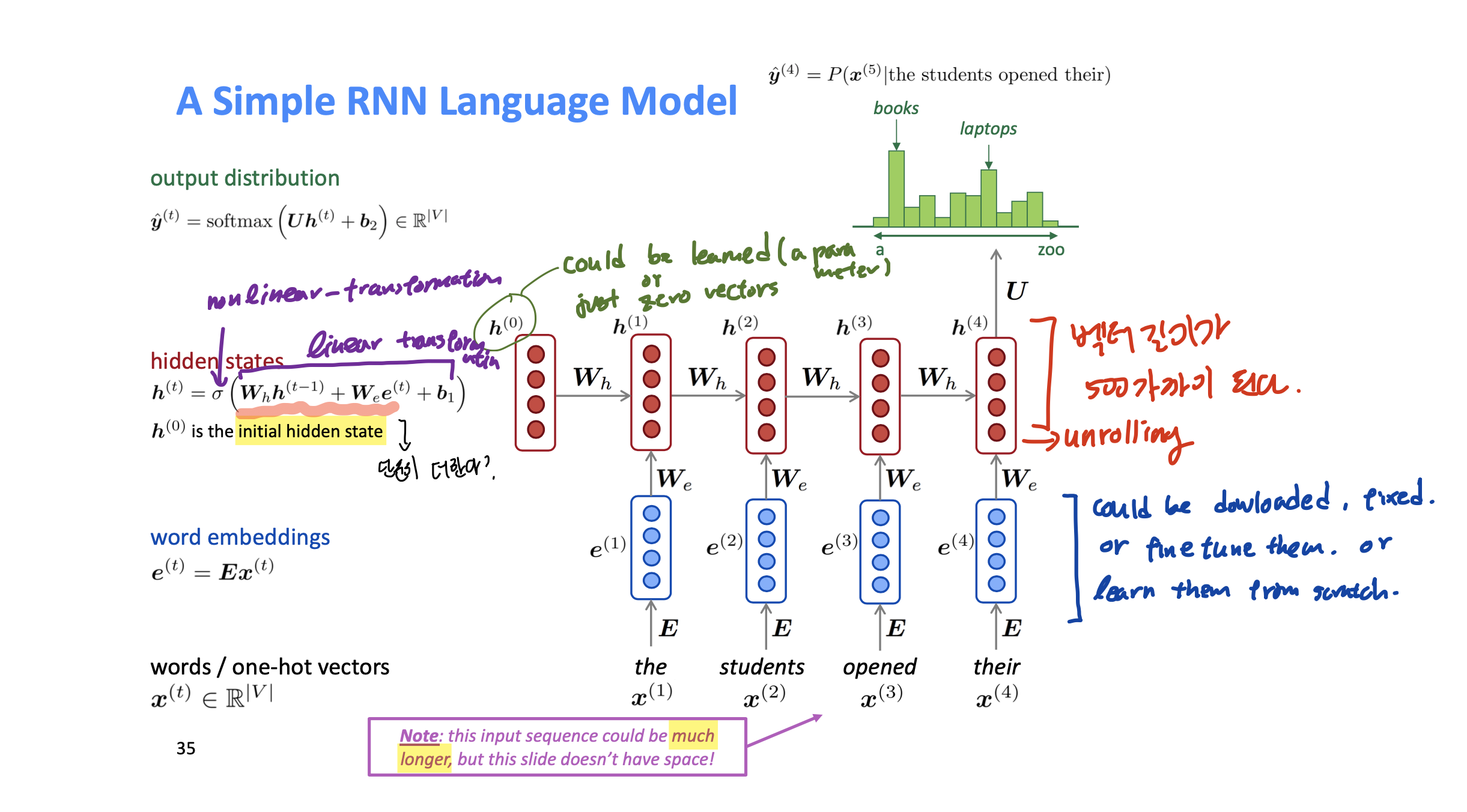
input size는 데이터에 따라서, 어떤 효과를 원하냐에 따라서 짧게 할 수도, 길게 할 수도 있다. 그리고 그 길이는 W_h에 영향을 미치지 않는다.
Rnn의 로스는 각각 hidden state의 결과인
또한 batch Gradient Descent를 적용한다.
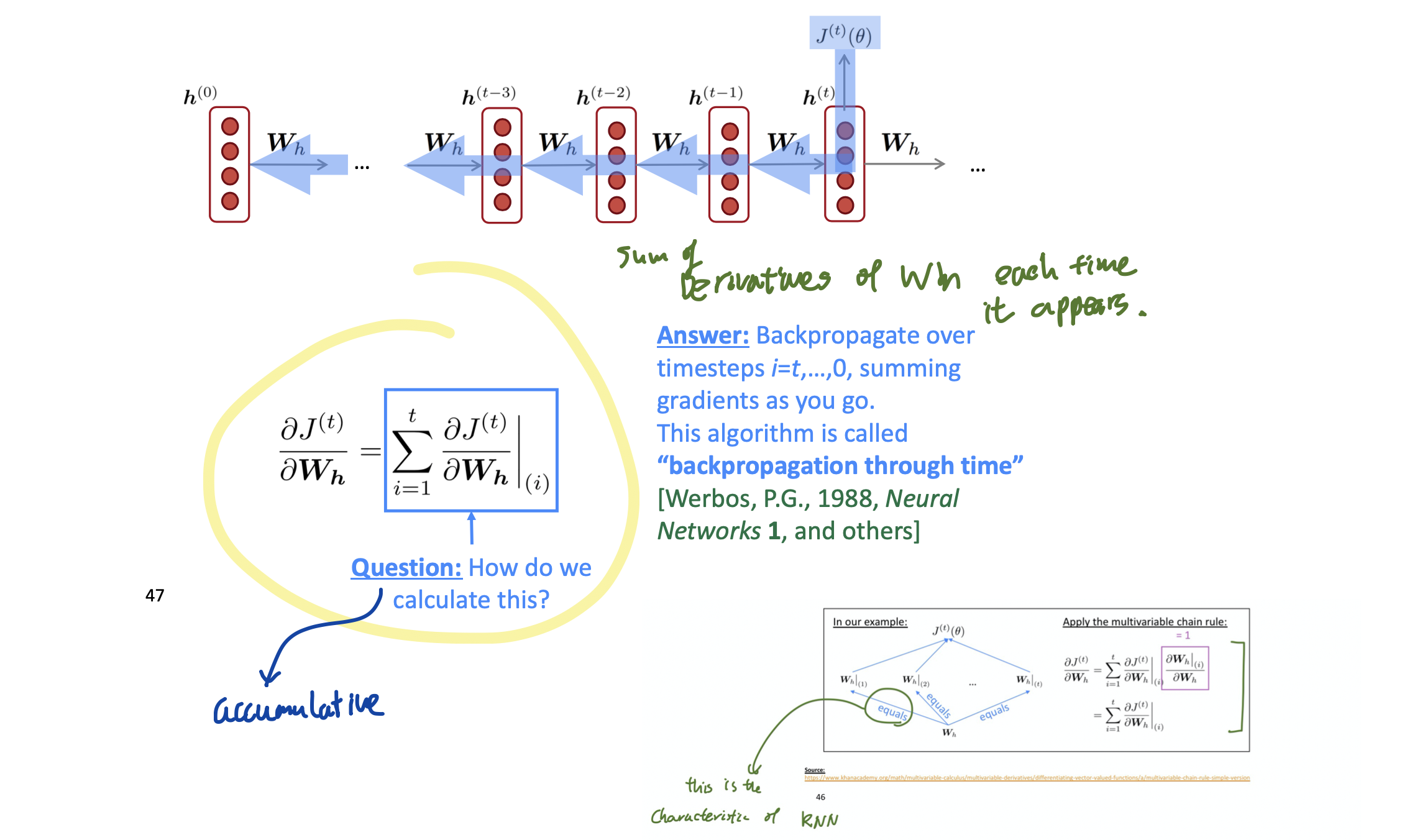
# Back Propagation through time
이 슬라이드 하나면 충분해요
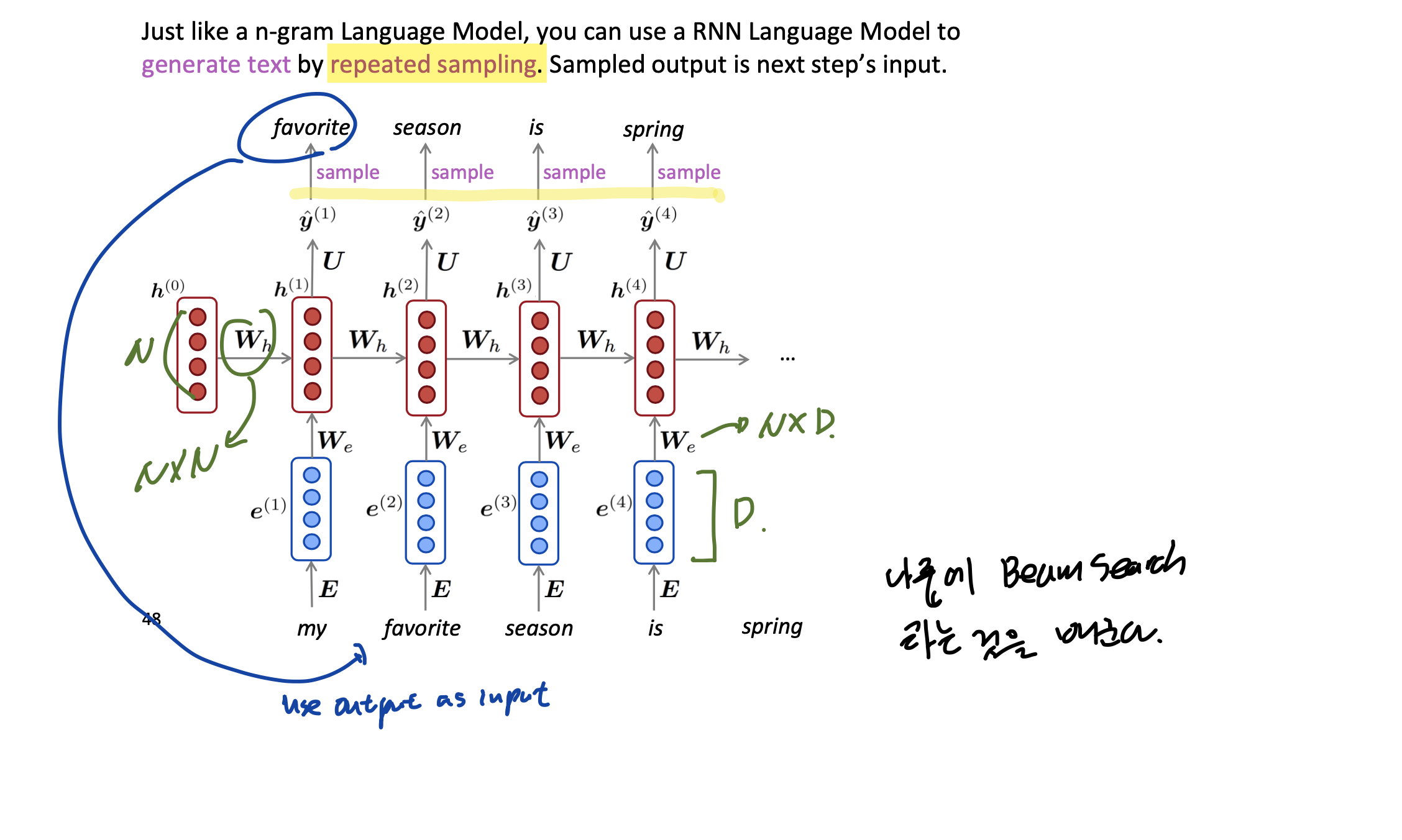
# Generating Text with RNN
Repeated sampling 이라는 것을 이용해서 텍스트를 산출할 수 있다.
요것이 재밌는 것이, RNN-LM 을 어떤 데이터로 학습시켰냐에 따라서 그 데이터의 스타일 대로 산출할 수 있다는 것이다(오바마 연설체, 문체 등을 배낄 수 있다는 얘기)
그러나 예시를 보면 아직은 꽤 incoherent 하다는 것을 알 수 있다.
# Perplexity

왜 LM이 중요한가?
- Language Modeling은 실제 언어를 이해하는데 대한 benchmark task다. LM이 보다 좋은 성능을 낸다는 것은 어느 부분에서 Natural Language Understanding에 progress가 있었다는 것을 의미한다.
- 또한 LM은 다양한 NLP task의 subcomponent로 기능한다.
WARNING
RNN is not Language Model It could be used for variety of tasks such as pos tagging, NER, sentence classification, general purpose encoder module.
::: detail Question Answering을 할 때, question에 대한 encoder로 RNN을 사용할 수 있다. Speech Recognition을 할 때는, conditioning 을 거쳐 output을 생성한다. :::